首页
微服务
文章归档
关于
1
MyBatisPlus 一对多分页异常处理及性能优化
2
IntelliJ IDEA中运行Nacos官方源码
3
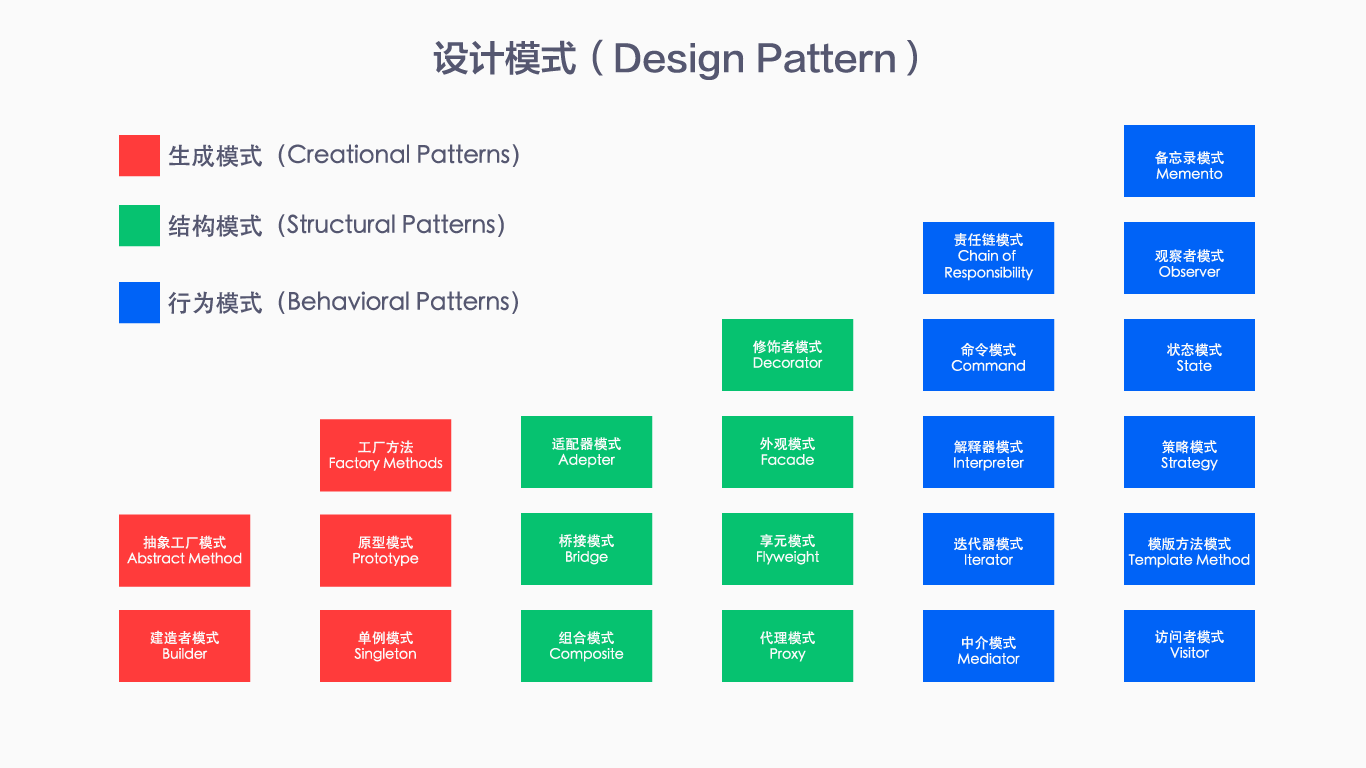
关于设计模式(About Design Pattern)
4
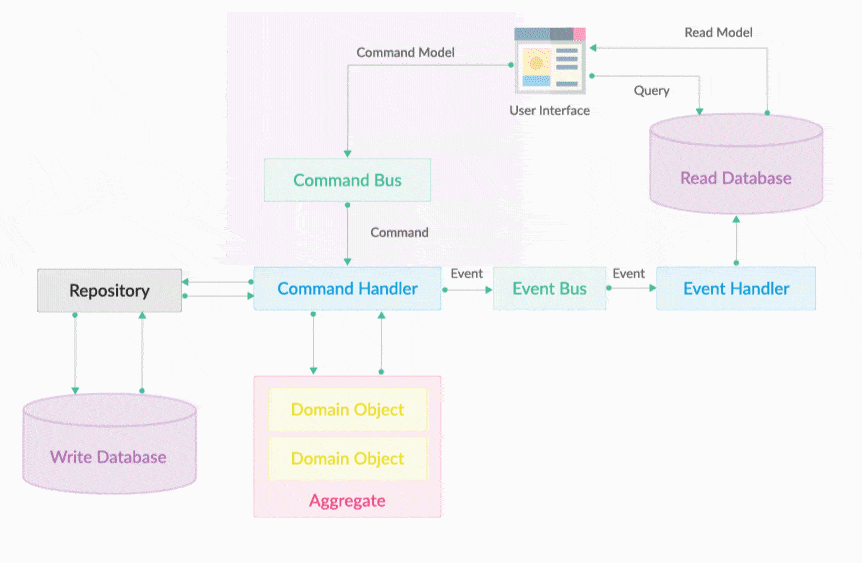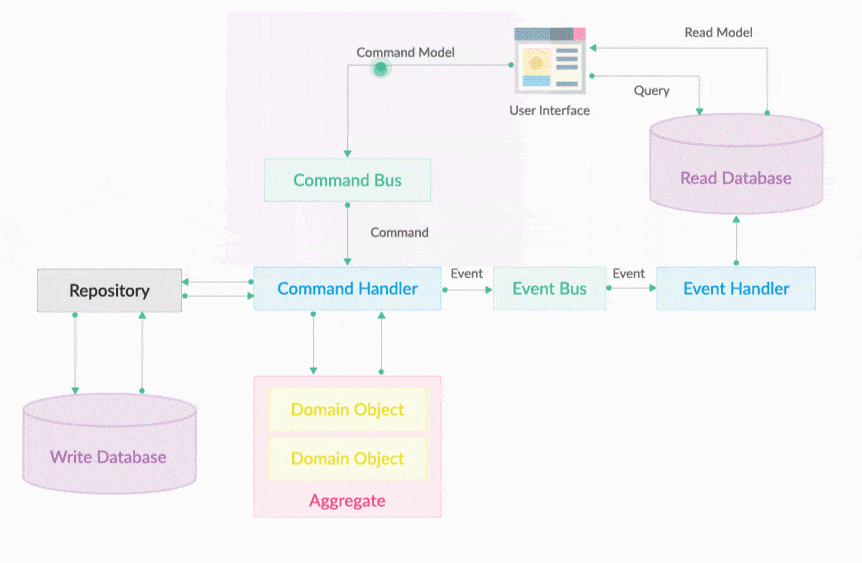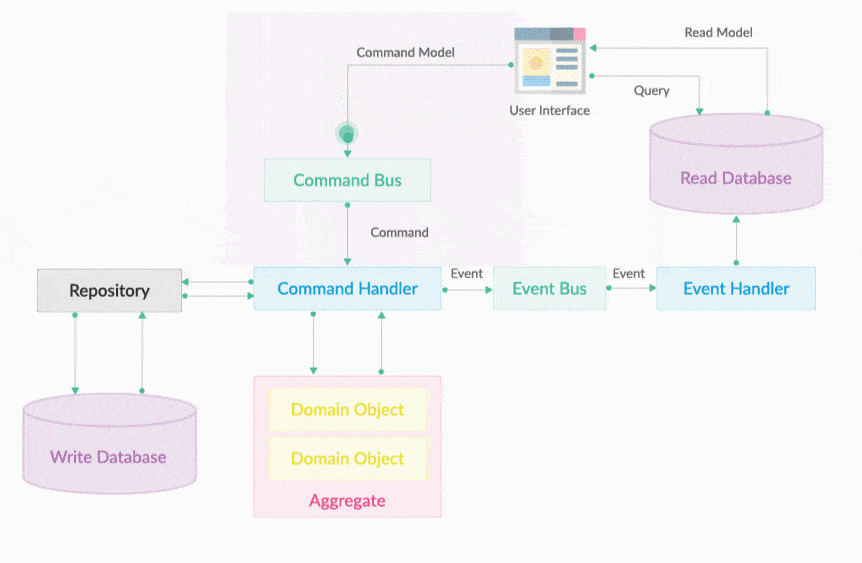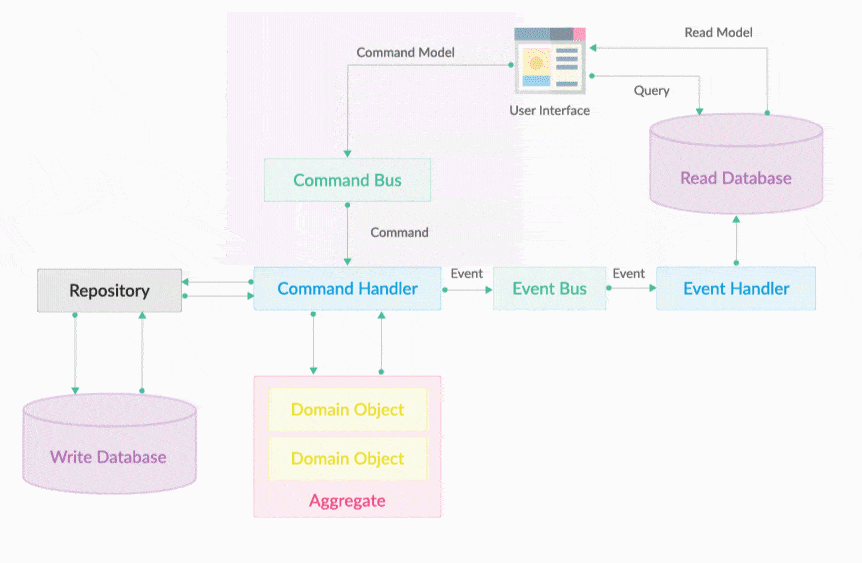
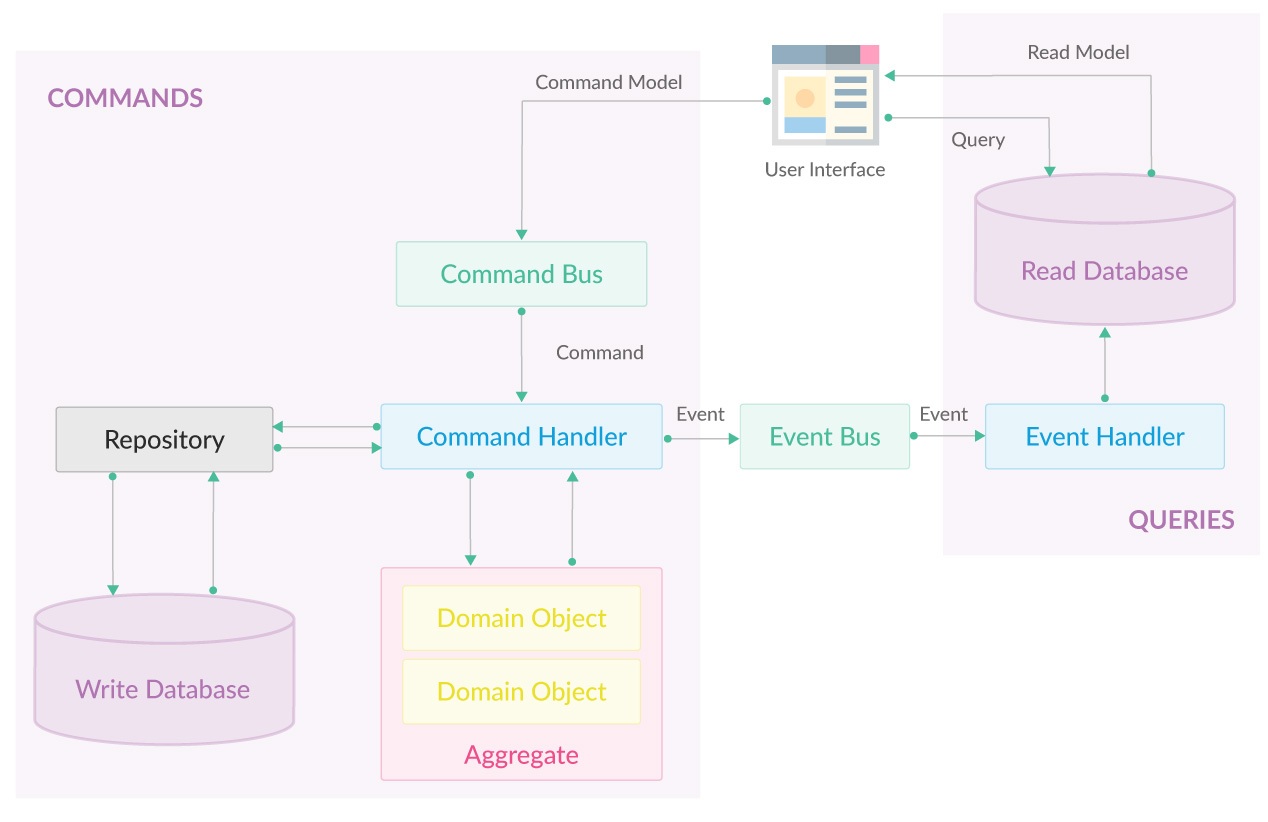
DDD-CQRS & Event Sourcing
5
使用Spring Boot和Axon实现CQRS&Event Sourcing
树下魅狐
是技术也是艺术
累计撰写
16
篇文章
累计创建
13
个标签
累计收到
12
条评论
栏目
首页
微服务
文章归档
关于
搜索
标签搜索
MyBatis
设计模式
MQ
NPM
Nodejs
Vue
MySQL
SpringCloud
Nacos
Java
SpringBoot
分布式
微服务
MyBatisPlus 一对多分页异常处理及性能优化
IntelliJ IDEA中运行Nacos官方源码
关于设计模式(About Design Pattern)
DDD-CQRS & Event Sourcing
使用Spring Boot和Axon实现CQRS&Event Sourcing
精品分类
全部分类
8 ℃
微服务
7 ℃
默认分类
2 ℃
后端
0 ℃
前端
最新文章
热门文章
最近更新
最多点赞
暂无文章数据
加载中...