



场景描述:
- 现有三张表:账户表(t_account),账户-角色关联表(account_role_link)和角色表(t_role)
- 对角色表进行分页查询并附带查询条件
- 查询结果需要关联角色对应的账户数据
1.异常情况
角色和用户存在一对多关系,可以使用collection对多个账户数据进行处理。对角色数据的封装如下(Java):
public class RoleVO {
private String id;
private String name;
private String code;
private List<UserVO> users;
//此处省略getters&setters
}
public class UserVO {
private String id;
private String username;
//此处省略getters&setters
}
RoleMapper.xml中的查询语句如下:
<resultMap id="UserVOMap" type="com.ramostear.console.domain.vo.UserVO">
<id property="id" column="uid"/>
<result property="username" column="username"/>
</resultMap>
<resultMap id="RoleVOMap" type="com.ramostear.console.domain.vo.RoleVO">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="code" column="code"/>
<result property="status" column="status"/>
<result property="remark" column="remark"/>
<result property="createTime" column="create_time"/>
<result property="modifyTime" column="modify_time"/>
<collection property="users" resultMap="UserVOMap"/>
</resultMap>
<select id="queryPage" resultMap="RoleVOMap">
SELECT t_0.*,t_2.id AS uid,t_2.username
FROM t_role t_0
LEFT JOIN account_role_link t_1 ON t_0.id = t_1.role_id
LEFT join t_account t_2 ON t_2.id=t_1.account_id
<where>
<if test="keyword != null and keyword != ''">
AND t_0.name LIKE CONCAT('%',#{keyword}, '%')
</if>
<if test="status != null">
AND t_0.status=#{status}
</if>
</where>
ORDER BY t_0.create_time DESC,t_0.modify_time DESC
</select>
当前角色表中有13条数据,分页查询时,每页展示10条数据,执行查询,结果如下(JSON):
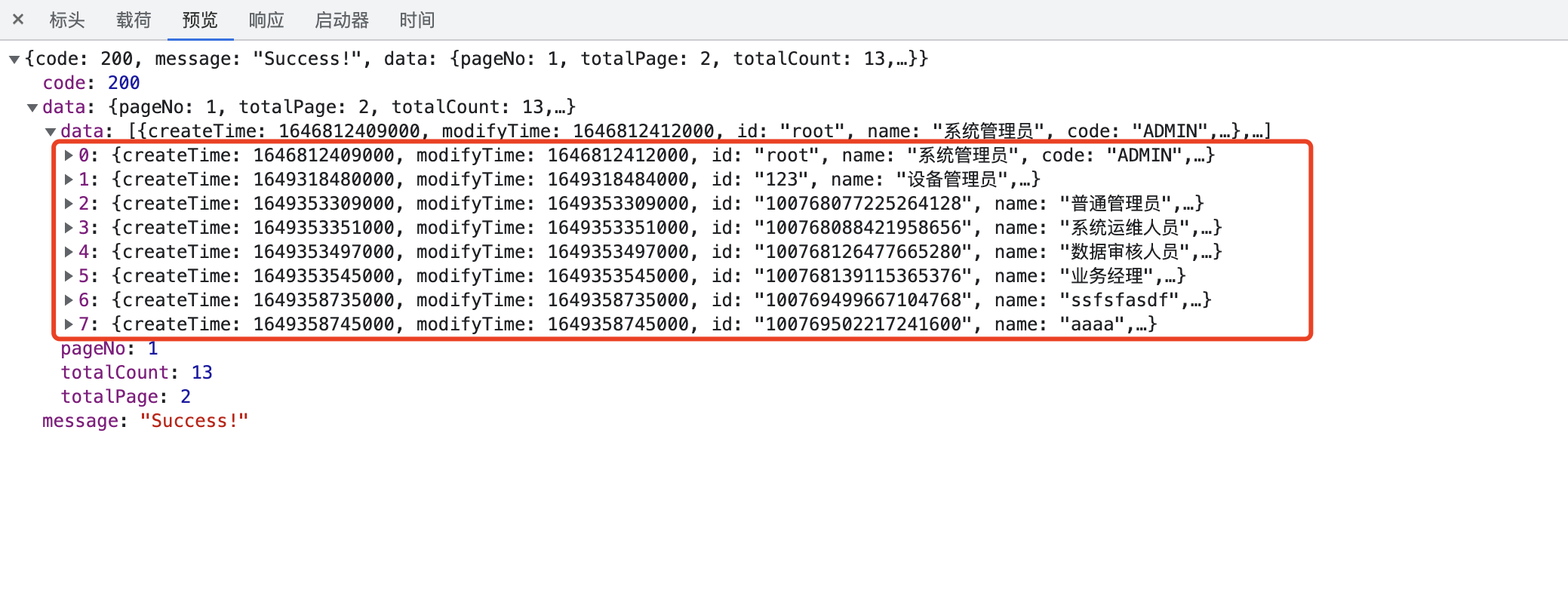
正常情况下,查询的结果中应该是10条角色数据,但此时只有8条(和预期结果有出入)。再观察控制台输入的SQL语句:
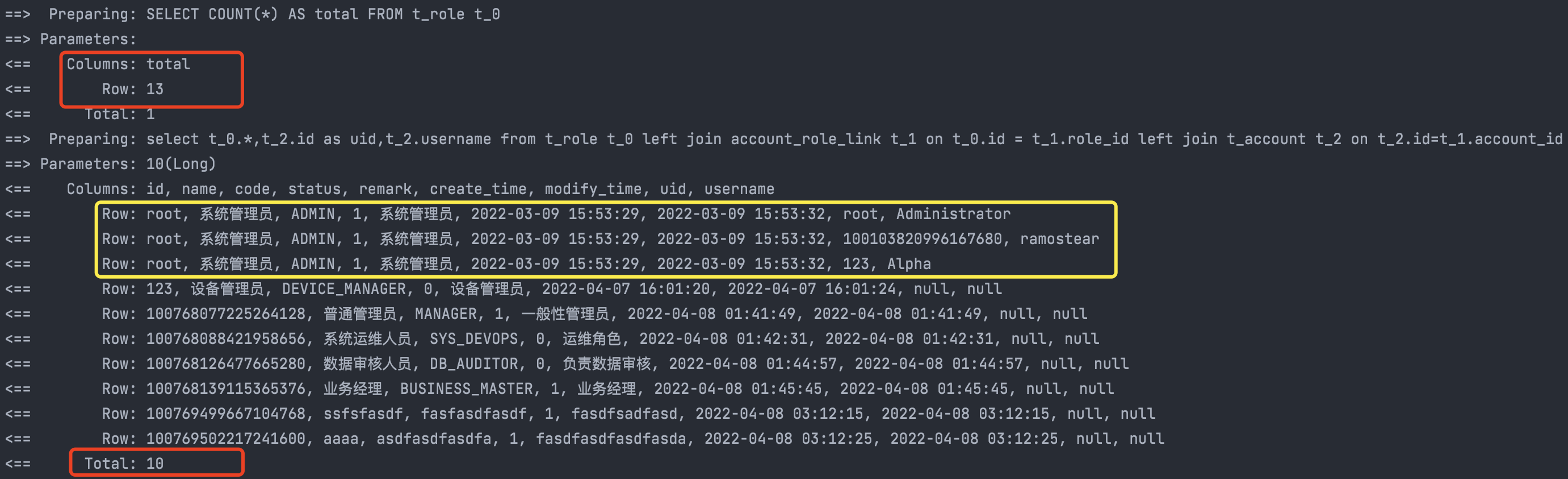
角色数据总数:13条,分页查询条数:10条,从查询结果数量上看,SQL没有问题。但黄色框中的数据会有一个小坑。
上述的SQL写法,是对角色和账户两张表JOIN后的结果集进行了分页(10条,其中有三条角色数据是重复的),而我们最开始的需求是对角色数据进行分页查询并带上角色对应的账户数据。Mapper中的collection在处理结果集时,会对黄色框中的数据进行合并收集(一对多处理),在进行实体对象映射时,MyBatisPlus将三条角色重复而用户不同的数据合并为一个RoleVO对象实例,这就导致了最终拿到的查询结果只有8条数据。
导致这个问题,是我们把原先对角色数据进行分页的需求,变成了对角色和账户JOIN后的数据进行分页,且在返回最终结果前,MyBatis 的collection又把数据进行了“合并”。
解决该问题的重点就是:对角色分页!对角色分页!对角色分页!
2.使用子查询
找到问题的所在,我们不应该对JOIN后的结果进行分页处理,而是先对角色数据进行分页处理,然后再处理角色和账户的一对多映射。
使用MyBatis提供的子查询,主表(t_role)查询不参杂对t_acctount表的处理,t_role表分页查询处理完成后,传递ro leId到子查询中,对关联的账户数据进行查找。
# ============================ 改造后的ResultMap =========================
<resultMap id="RoleVOMapBySubQuery" type="cn.zysmartcity.console.domain.vo.RoleVO">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="code" column="code"/>
<result property="status" column="status"/>
<result property="remark" column="remark"/>
<result property="createTime" column="create_time"/>
<result property="modifyTime" column="modify_time"/>
<collection property="users" ofType="com.ramostear.console.domain.vo.UserVO" column="roleId" select="queryUserByRole">
<id column="uid" property="id" jdbcType="VARCHAR"/>
<result column="username" property="username" jdbcType="VARCHAR"/>
</collection>
</resultMap>
# ============================ 主表的查询语句 =========================
<select id="queryPageBySubQuery" resultMap="RoleVOMapBySubQuery">
SELECT role.*,role.id as roleId FROM t_role role
<where>
<if test="keyword != null and keyword != ''">
AND role.name LIKE CONCAT('%',#{keyword}, '%')
</if>
<if test="status != null">
AND role.status=#{status}
</if>
</where>
ORDER BY role.create_time,role.modify_time DESC
</select>
# ============================ 子表的查询语句 =========================
<select id="queryUserByRole" resultMap="UserVOMap">
SELECT t_1.id AS uid,t_1.username FROM account_role_link t_0
LEFT JOIN t_account t_1 ON t_1.id=t_0.account_id
WHERE t_0.role_id=#{roleId}
</select>
主表查询中role.id as roleId既为ResultMap中定义的需要传递到子查询queryUserByRole的roleId参数
执行SQL查询语句,观察返回的结果集:
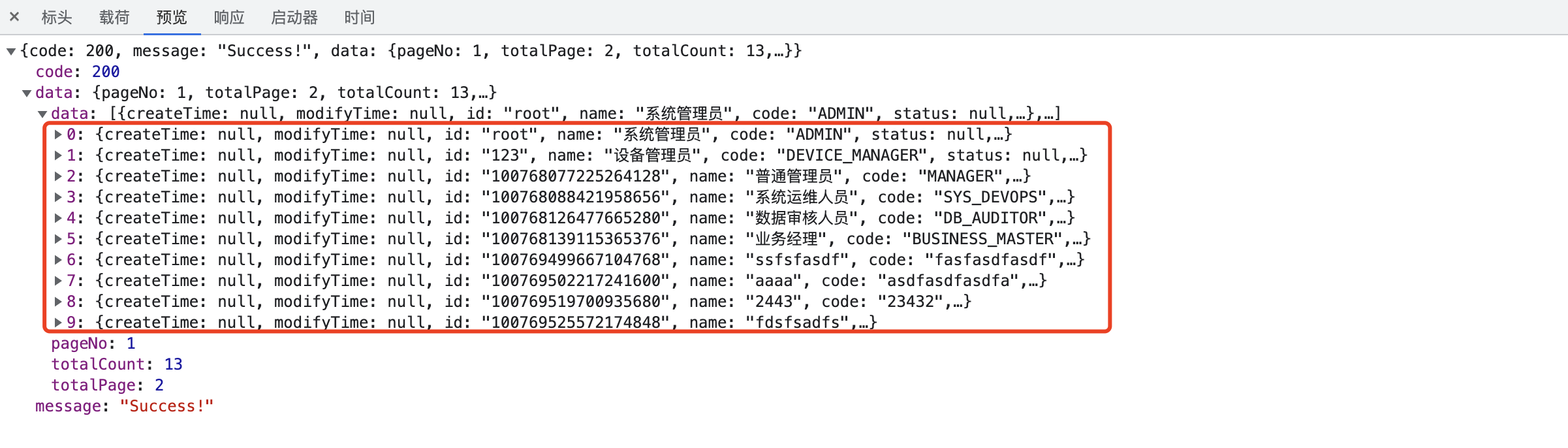
数据总数:13条,当前查询条数:10条,分页异常的问题得以解决;但是,问题还有完全解决,我们先看控制台输出的SQL语句:
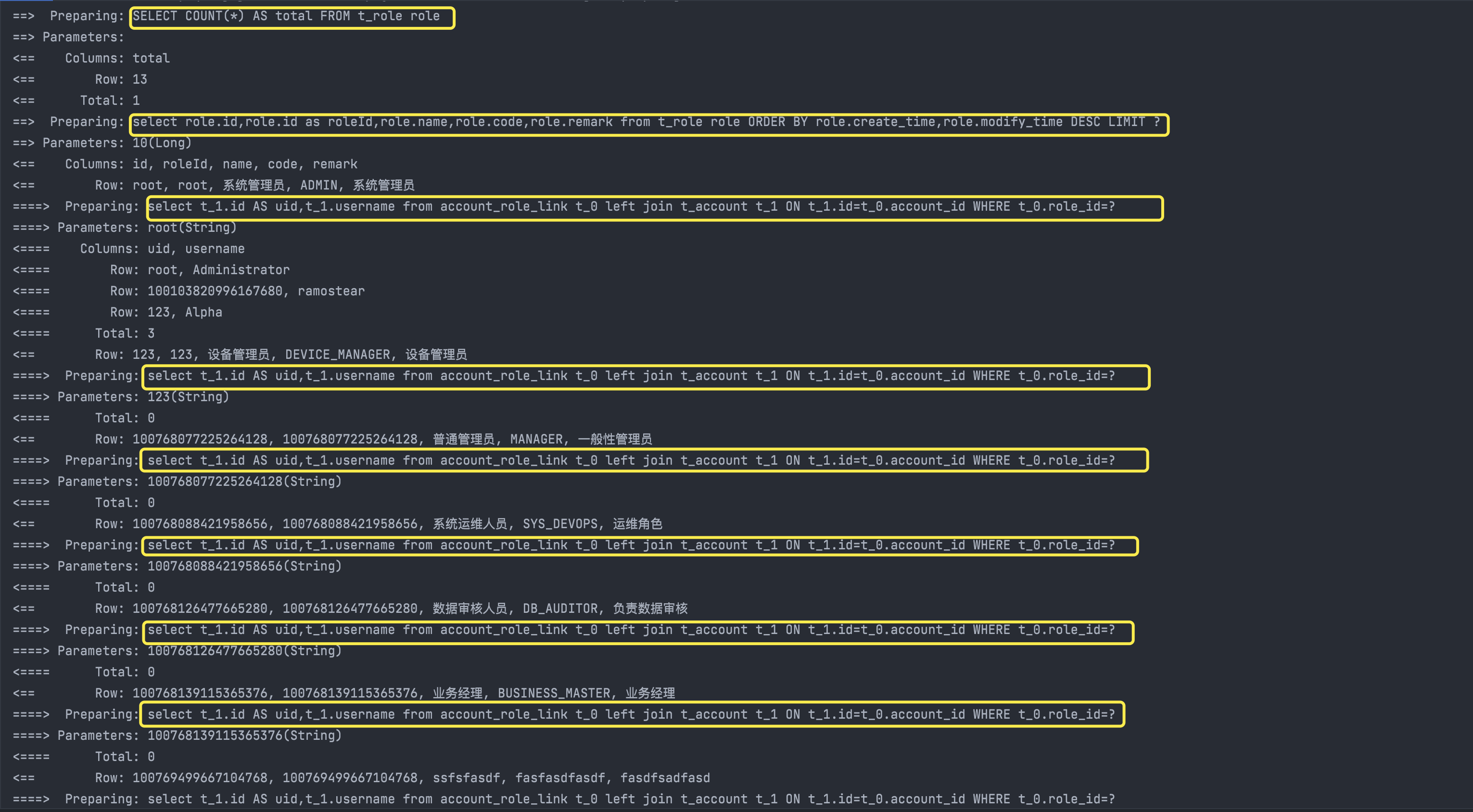
原本只需要发2次SQL语句(统计总数和分页)的查询,现在变成了发N+1条SQL语句(N为分页大小),再看执行的时间
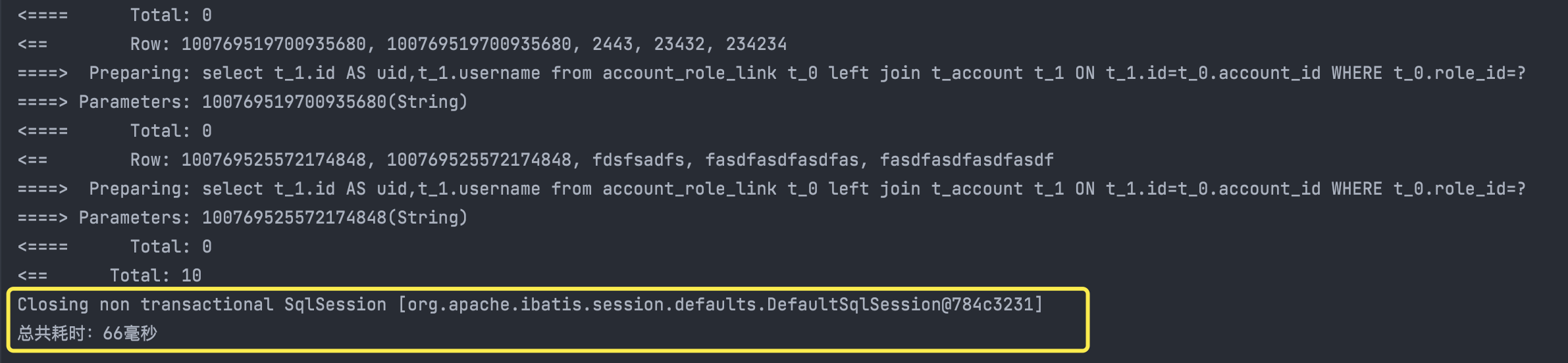
13条数据分页查询,耗时66毫秒,如果数据更多呢?每页显示数据量更大呢?子查询的这种方式显然是不太合理的。
3.自定义分页
解决思路:先对角色表进行分页查询,得到的结果集再和账户进行JOIN操作。
去掉ResultMap中colletion的column和select属性,保持和最开始的ResultMap一致:
<resultMap id="UserVOMap" type="com.ramostear.console.domain.vo.UserVO">
<id property="id" column="uid"/>
<result property="username" column="username"/>
</resultMap>
<resultMap id="RoleVOMap" type="com.ramostear.console.domain.vo.RoleVO">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="code" column="code"/>
<result property="status" column="status"/>
<result property="remark" column="remark"/>
<result property="createTime" column="create_time"/>
<result property="modifyTime" column="modify_time"/>
<collection property="users" resultMap="UserVOMap"/>
</resultMap>
调整查询语句如下:
<select id="queryPageRecords" resultMap="RoleVOMap">
SELECT t_0.*,t_2.id AS uid,t_2.username
FROM (
# ===========处理角色的分页==============
SELECT t.id,
t.name,
t.code,
t.status,
t.remark,
t.create_time,
t.modify_time from t_role t
<where>
<if test="keyword != null and keyword != ''">
AND t.name LIKE CONCAT('%',#{keyword}, '%')
</if>
<if test="status != null">
AND t.status=#{status}
</if>
</where>
ORDER BY t.create_time,t.modify_time DESC
LIMIT #{offset}, #{size}
) t_0 # =======角色分页后的结果集,在同账户进行JOIN==========
left join account_role_link t_1 on t_0.id = t_1.role_id
left join t_account t_2 on t_2.id=t_1.account_id
</select>
offset和size是上层(controller -> service)传递的分页参数,可以从Page
中获取到
改造后,我们还需要手动去统计一下角色表的数据总量(查询条件需要和分页查询中保持一致),最终改造如下:
RoleService.java
public class RoleService {
//此处省略其他代码....
public Page<RoleVO> queryPage(String keyword,int status,Page<RoleVO> page) {
//执行分页查询
List<RoleVO> records = baseMapper.queryPageRecords(keyword, status, page.offset(), page.getSize());
//统计数据总数
LambdaQueryWrapper<Role> queryWrapper = new LambdaQueryWrapper<Role>()
.eq(status != null, Role::getStatus, status)
.like(StringUtils.isNotEmpty(keyword), Role::getName, keyword);
long total = this.count(queryWrapper);
//设置分页数据
page.setRecords(records);
page.setTotal(total);
return page;
}
}
执行SQL查询语句,观察返回的结果集:
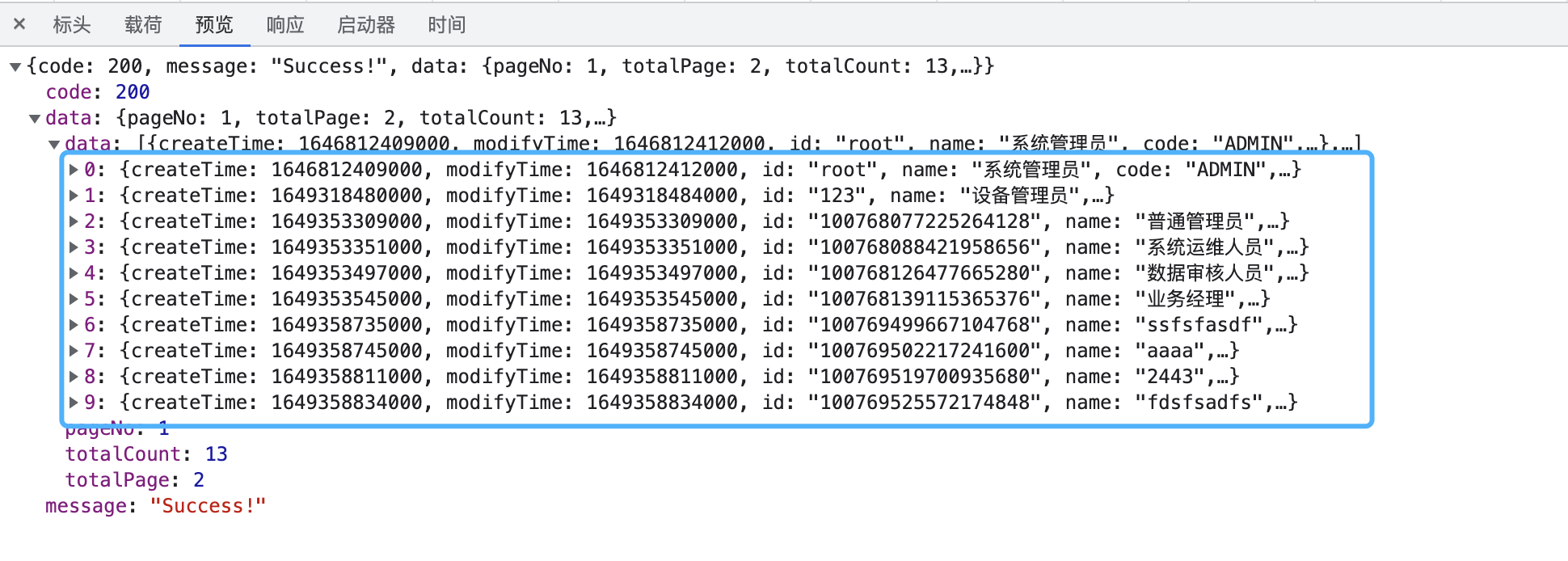
数据总数:13条,当前查询条数:10条,返回数据正常,再观察控制台SQL日志和消耗的查询时间:
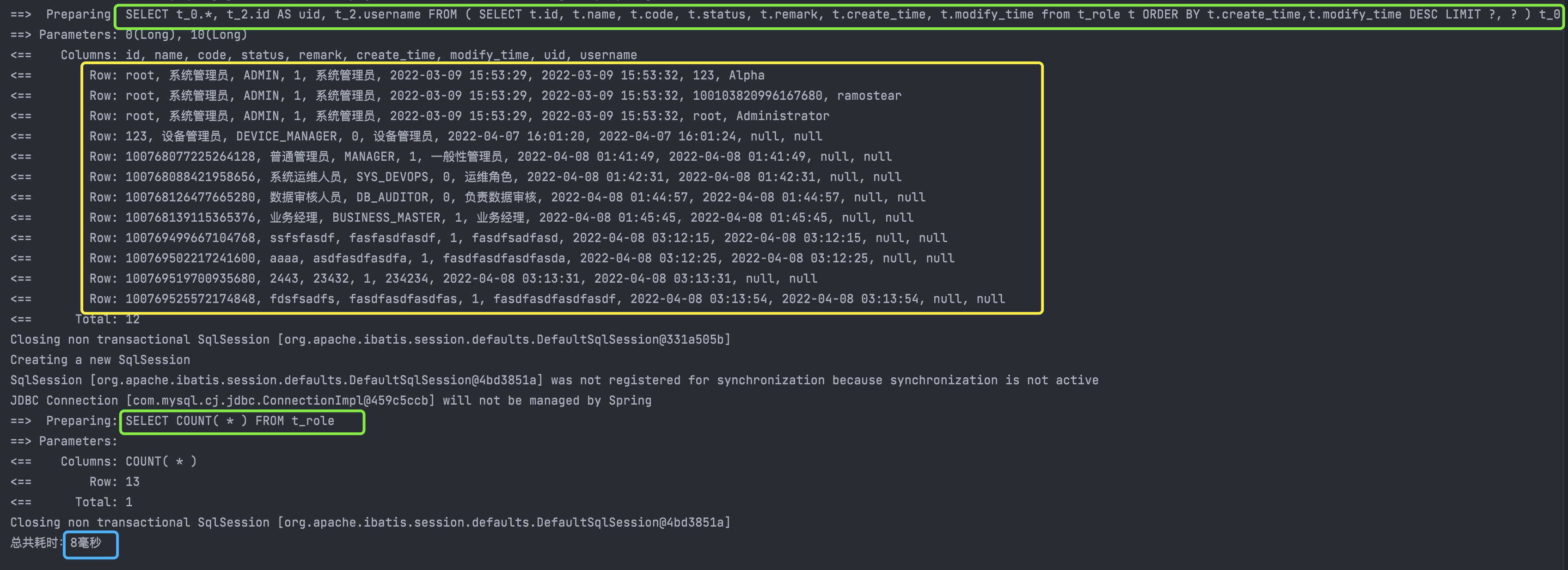
共发送了2次SQL语句,查询结果集为13条数据(3条角色重复,一对多合并后10条数据),耗时 8毫秒,相较之前的66毫秒,速度提升了不少,且减少了发SQL的次数。
评论区